

Datasets
Do you ever notice how much important the datasets are? Well, our today’s discussion is to surprise you with this highly trending matter. Are ready to go?
So, let’s tunned until the end.
With Google Cloud, what does a dataset mean?
Wherever a dataset resides, it remains a dataset.
To put it simply, a dataset for machine learning is a group of data points that a computer can analyze and forecast as a single entity.
Imagine an Excel spreadsheet that contains 1000 rows. That dataset is comprehensive.
Why is accurate analysis crucial to data science?
Since it offers an exacting mathematical framework for comprehending and analyzing data, real analysis is a crucial tool for data science.
With the use of real analysis, we are able to make exact claims on the size, shape, & structure of datasets.
We may utilize these patterns to anticipate the future or derive inferences from the data by recognizing patterns in massive datasets.
We may get insights into how various variables interact with one another within a dataset by applying practical analytical tools like calculus & linear algebra. This can help us make judgments about how to use the data most effectively.
What is the role of data science, With respect to datasets?
Since it offers an exacting mathematical framework for comprehending and analyzing data, real analysis is a crucial tool for data science.
With the use of real analysis, we are able to make exact claims on the size, shape, & structure of datasets.
We may utilize these patterns to anticipate the future or derive inferences from the data by recognizing patterns in massive datasets.
We may get insights into how various variables interact with one another within a dataset by applying practical analytical tools like calculus & linear algebra. This can help us make judgments about how to use the data most effectively.
What is a dataset?
Where can I obtain big datasets to aid in my machine-learning education?
1.0 Datasets from Kaggle
For Data Scientists & Machine Learners, Kaggle provides one of the greatest sources of datasets. It makes it simple for users to locate, download, and publish datasets. Moreover, it offers the chance to collaborate with some other machine learning professionals and complete challenging Data Science-related projects.
We can quickly locate and download a high-quality dataset from Kaggle in a variety of formats.
2.0 Machine Learning Repository at UCI
One of the best places to find machine learning datasets is the UCI Machine Learning Repository. The machine learning community frequently uses this repository to store datasets, domain theories, and data generators for use in analyzing ML algorithms.
It categorizes the datasets in accordance with machine learning issues and tasks like regression, classification, clustering, and so on.
Also, it includes some well-known datasets, like the Poker Hand, Iris, and Vehicle Assessment datasets.
3.0 Through AWS, datasets
The datasets which are made accessible to the public via Amazon resources can search, downloaded, accessed, and shared. Access to these datasets is possible via Amazon services,
however, various governmental agencies have issues. like academic institutions, enterprises, or private citizens.
With shared data and Amazon resources, anybody may evaluate and create a variety of services. Cloud-based shared datasets enable users to focus more on data analysis and less on data collection.
This source offers examples and usage guidelines for the different dataset types. Also, it has a search bar so that we may look for the needed dataset. The Registry with Open Data on AWS is open for anybody to contribute any dataset or example.
I need data for machine learning, where can I find it?
There are several datasets of historical importance because machine learning was already researching for many years. The UCI Machine Learning Repository ranks among the most popular repositories for these datasets.
Because, technology at the moment was not achievable sufficiently to handle greater size data, the majority of the datasets available there really are modest in size. This repository contains some well-known datasets, including the iris flower dataset.
Well,
Newer datasets typically have bigger sizes. The ImageNet dataset alone is more than 160 GB. These datasets may be searched for by name in Kaggle and are frequently found there. Using Kaggle’s command line tool upon creating an account is advised when we require to download them.
Several datasets are housed in the more recent OpenML repository. It is practical since you can look up a dataset by title, but users can also access the data via a defined web API. Weka offers files in the ARFF format, therefore it would be helpful if you wanted to use it.
However, despite this, there are still lots of datasets that are accessible to the public but are not stored in these repositories.
Check to see Wikipedia’s “List of datasets with machine-learning research” as well. On that website, you may download a vast list of datasets that can categorize into many subcategories.
Retrieving Datasets in Seaborn and Kit-Learn
In a trivial manner, you can retrieve those datasets by collecting them from the internet using a browser, a command-line program, the wget utility, or network libraries like requests in Python.
Some machine learning libraries offer methods to assist with retrieval since a few of these datasets have evolved into industry benchmarks or standards. The datasets are frequently retrieved in real time whenever you call the functions rather than being distributed with the libraries for practical reasons.
As a result, to utilize them, you need a reliable internet connection.
instead, Let’s do it in a simple manner,
Another option is…
Data gov
You may wish to check out what the government has made available to the public while seeking data science datasets. If these data are used wisely, they could lead to ideas that benefit your nation in its entirety.
The United States government creates an open data lake = Data Gov. where public data are available to enhance scientific research and development. In order to make it simple to explore and discover the data you need, the Data gov has data divided into themes like health, energy, and education.
How can I acquire datasets for machine learning models?
There is more than just text data collecting in the data set. Data Set Collection generally comprises Voice Data Collection, Video Data Collection, Picture Dataset Collection, and Video Dataset Collection. Let’s take a short drive to these data repositories.
1.0 Data collection for speech and audio
Voice and speaking patterns vary from person to person. Their dialect, pronunciation, tempo, and intonation vary. The development of automatic speech recognition systems is extremely challenging due to these factors.
AI Speech Data Collection identifies how individuals construct and speak directions to voice assistants. when they react to and remark on speech recognition technologies, how they pronounce and emphasize pre-defined words.
and how well they comprehend sentences whether they are spoken by people from diverse backgrounds and with varying background noise.
So, Your audio-based systems must receive the best AI training possible due to their dynamic nature.
2.0 Gathering video data sets
It’s crucial to collect lots of high-quality training data in order to develop AI-based surveillance, motion detection, as well as;
- gesture guidance systems.
- Motion pictures,
- gestures,
- sporting events,
- scenes and things,
- animals and many other types of information
are all included in this data? A lot of video data sets, video recordings, lighting circumstances, tailored training data, and quality checks are the main AI emphasis areas.
3.0 Image Dataset Collection
To effectively detect and evaluate photos used for machine learning, every AI system has to train using relevant and model-specific photo data sets.
For all types of deep learning and machine learning applications, a comprehensive range of photo dataset collection & annotation must be covered.
As trained computer vision models using one of the most complete picture datasets plus deep learning images prefer a wide range too.
What does gathering and analyzing data entail?
Data analysis looks for patterns & trends in datasets; data collection is the systematic capturing of information and data interpretation is the process of describing such patterns and trends.
Can deep learning use pretty small datasets?
Yes and no!
The fact here is when you want more accuracy, use bigger datasets.
Got it?
Every dataset may use for deep learning. Nevertheless, the dataset’s size and quality have an impact on how well the algorithm works. Higher performance may ensure more data. To strengthen the dataset, better processing methods and augmentation have to use.
By the way, when you are o the task, bit careful about overfitting data facts.
Here is Why?
How do we recognize an overfitting model?
When a model completely matches the training dataset, this is known as overfitting. Despite the fact that it would seem appropriate, this is not the case. The model performs significantly worse with unknown data when it overfits.
When a model flawlessly matches the training dataset but performs badly on fresh test datasets, it is said to be an “overfit”.
On the other side,
underfitting occurs when a model hasn’t been trained for long enough to identify useful patterns within training data. To a great extent new and untested datasets, neither overfitting nor underfitting may use.
How to Detect overfitting data?
This is a similar widespread issue, it’s better to identify Overfitting. It has to apply to test data in order to be able to detect overfitted data. The dataset must initially split into two distinct sets for training and testing as the first stage in this process.
It is obvious that a model overfits. if it outperformed the test set by an exponential amount.
Next, a separate test set can use to assess the model’s performance. Using Scikit-Train-Test learns split methodology, this measurement was carried out. An artificial classification dataset is outlined in the initial stage.
After that, the classification method is used to divide the classification prediction issue into two halves, with rows on one side & columns on the other.
then by running this example. it creates a dataset.
The dataset is then divided into test and train subsets, with 70% used for training and 30% for assessment.
For overfitting, by selecting a machine learning model. It provides a comment on the accuracy ratings of the model in relation to how well the performance with test sets is at the conclusion.
For the purpose of obtaining an average result, the example will run several times.
What distinguishes a test set from a validation set?
We commonly divide a dataset into three pieces when we apply some machine learning algorithm to it.
- The model was trained using the training set.
- To improve model parameters, use the validation set.
- Test Set: Used to obtain a fair assessment of the performance of the final model.
These three various dataset types; illustrates in the diagram that follows:
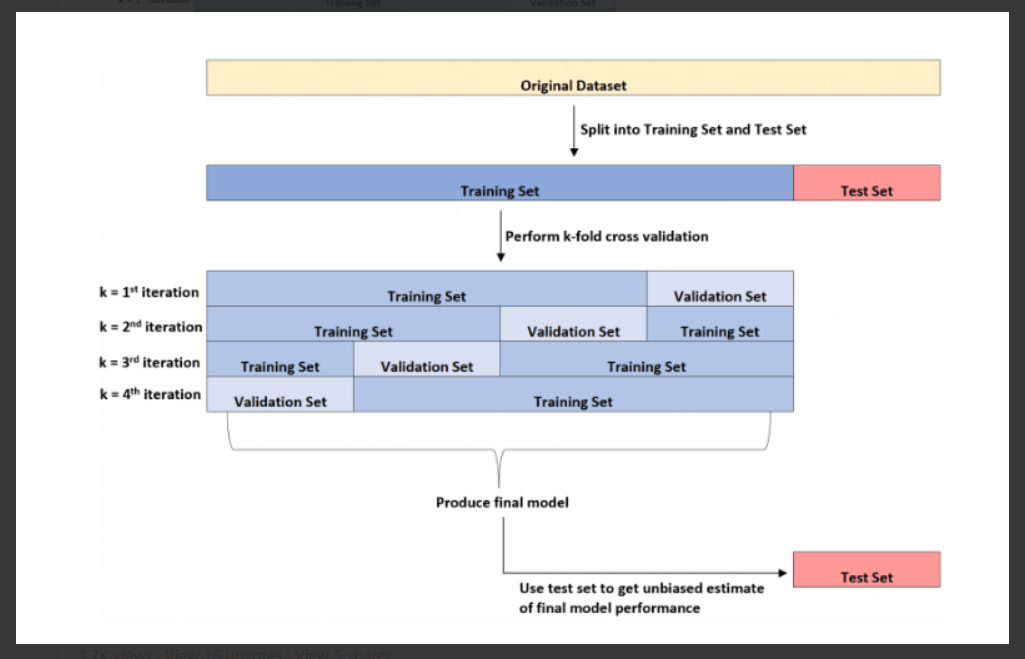
The distinction between the test set and the validation set is one area that causes students trouble.
In layman’s words, the test set serves to offer an unbiased approximation of the final model while the validation set acts to improve the model parameters.
After the model is put into effect on an unknown dataset, it can demonstrate that the error value as evaluated by the k-fold validation set frequently underestimates the real error rate.
In order to obtain a fair estimation of the genuine error rate in the real world, we thus fit the final product to a test set.
Well, let’s move on to a crucial point…
How do we use it for business purposes?
All firm has to have a sales projection. Data science is frequently using in applications like this. Every company will keep a record of its sales data, whether it performs on a daily, weekly, monthly, or another basis.
This knowledge aids in supporting numerous business choices like;
- How much stock should I have? Which warehouse should they visit first? How frequently should each site restock?
- How much money can each product be projected to make from sales in a specific time period?
- Is the sales goal being attained?
- Do the sales outweigh the expenses and resources incurred by the marketing efforts?
A business can handle sales forecasts Using suitable datasets
Yes, it is…
For the business to be able to make future plans, it is crucial to have accurate sales predictions. The amount of sales data may be quite large, whatever the size of either company.
Even for smaller businesses, the quantity of the dataset is sometimes lower, yet the particular model types that can use to produce precise forecasts are fairly complex.
With data science tools, you may finish this sort of assignment. To begin with, you need to pre-process the information to ensure there;
- aren’t any missing data,
- all parameters are in corresponding units,
- any required rows or columns should merge or remove, etc.
To get useful information from the data, it has to collect properly.
Next, you would do an exploratory analysis of the data on it, during which you would examine the data’s distribution, trends, and correlations with other variables, among other things.
Got it?
The model that best fits the data will become clear once you’ve done this.
Following that, you may apply predictive models to the dataset, including time series prediction using ARIMA modeling, any other model which you consider acceptable, or a minimal gradient enhancing machine framework that uses a decision tree method.
And you know this task is ok under fair qualification in data science.
so, What techniques do companies usually employ to guarantee the correctness of their datasets?
For verifying the correctness of their datasets, businesses frequently employ a range of techniques.
Among the most popular techniques are:
1.0 Data validation
Setting restrictions on the data which submits into a system entails making sure that it is formatted correctly or that email addresses have the “@” sign.
2.0 cleaning of data
This entails locating and eliminating redundant or incomplete data as well as fixing any mistakes or discrepancies.
3.0 Normalization of data
This calls for the consistent formatting of data, such as the conversion of all dates to an identical style or the guarantee that all addresses format uniformly.
4.0 Verification of the data
it examines several individuals to make sure it is correct and comprehensive.
5.0 Data auditing
It entails keeping track of any changes to the data, making sure they were done by authorized employees, and being able to track & trace those changes back to their original location.
6.0 Data Governance
This is a comprehensive strategy that involves establishing rules, responsibilities, and roles for how information is gathering, handling, and using inside an organization.
7.0 Automation
To eliminate human error and increase overall data accuracy, businesses can employ software solutions to automate the processes of data validation and cleansing.
Checks for data quality involve applying a series of criteria to the data to look for problems like missing numbers, incorrect values, outliers, etc.
These approaches are able to increase data accuracy because they are not exclusive of one another.
Summary
To sum up, you can now understand the basics of handling datasets. If you got the method, try to perform with a trial. later apply for the real purpose.
Hope, these insights on datasets will help
Cheers!
Check our related topics; Datafabric for business, synthetic data, data augmentation





